Vismut Core Rewritten
A brand new backend
For version 0.5 of Vismut, I rewrote Vismut Core, the backend library which handles all the node processing. The rewrite made Vismut Core easier to use, less buggy, and easier to maintain.
Before getting started, let’s define some words. These definitions are specific to Vismut Core, and may mean slightly different things in other contexts:
- DAG - Short for “directed acyclic graph”. It’s a collection of “nodes” and “edges”.
- Node - An operation that is performed as part of generating a texture. For instance “generate a noise image”, or “multiply two images together”.
- Edge - A connection between two nodes.
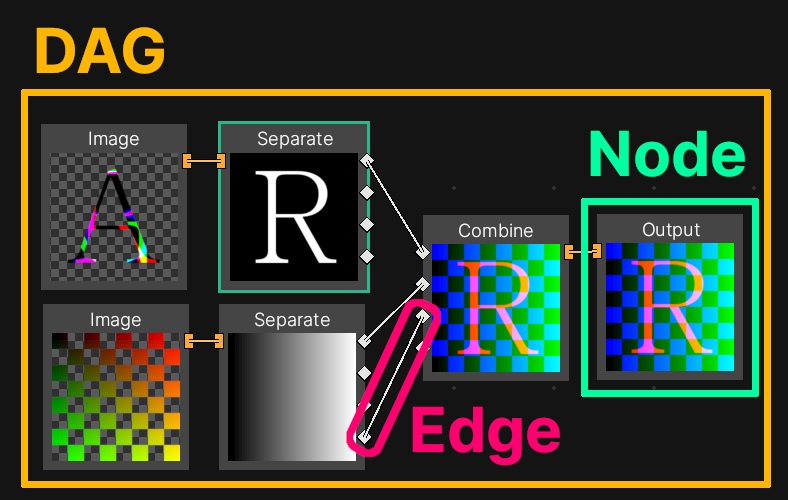
The Old Architecture
Here’s how the old architecture worked:
- The library provided a struct called “Engine”, which spawned a thread where it ran an update loop to calculate nodes.
- All the Engine’s data, like DAGs, edges, and nodes, were wrapped in
Arcs andRwLocks so they could be read and written to without needing to own the data. Accessing data like this between threads is called shared memory.

Running the Engine and the GUI on separate threads like this resulted in a GUI that was always responsive. However, there were significant downsides to this approach.
It wasn’t flexible. The library user wants to choose when the library runs. Running Vismut Core in its own thread makes sense for Vismut, but it isn’t a good choice in every case, like for the future command-line interface.
The types were annoying to work with. For instance, to read a node you needed to do something like this:
let my_node = engine.lock()?.node(node_id)?.node_type().lock()?;. That’s a lot of code for just getting a node, in the new architecture it’s more similar to this: let my_node = engine.node(node_id)?;.
I never managed to fix all timing bugs. Since changes could be made to the Engine at any point in the execution, changes could sneak in at unexpected moments, causing bugs. To avoid this, I tried to ensure I held locks in the Engine’s loop for longer, but these issues were very hard to debug. Holding locks for longer also meant the GUI had a harder time to get a lock, making the next issue worse.
Getting locks was unreliable. I never wanted to block when executing the user interface, so when getting a lock on the Engine, I just “tried” to get it and aborted if I couldn’t. However, the GUI only updates 60 times per second usually, so sometimes several frames would pass without being able to get a lock, leading to delays in the GUI.
So while the GUI was always responsive, sometimes you had to wait to see the results because it got unlucky with the locks. This didn’t play well with bevy_egui either, which is an immediate mode GUI library I’m using. If I couldn’t get a lock on the Engine to read data from it, I didn’t have any data to give to Egui, which caused parts of the GUI to flicker depending on if it could get a lock.
The New Architecture
Instead of spawning a thread in the library and running a loop there, the Engine is just a regular owned struct. We aren’t using any “shared memory” types like Arc and RwLock, except for a few Mutexes to ensure the Engine “is sync” so it can be sent between threads. The only time the Engine itself uses threads in the new architecture is when processing nodes.
Instead of forcing a constant loop, you get to manually call a “run” function to start calculating nodes. This gives the user control over when the Engine runs, and direct access to the Engine’s data. If you want to run it in a thread you can, and if you want to use shared memory you can, these choices are now left to the library user.

In the old architecture, the user was interacting directly with the same nodes and edges that the Engine used for processing. In the new architecture, there are three different “Worlds”. Each World is a different representation of all the nodes and edges in the Engine, each with its own purpose:
- Public World - the library’s interface
- Flat World - a world with only one DAG
- Live World - for processing nodes

The Public World is the most straightforward representation. This is the public interface, so this is where you add and edit your DAGs. It’s meant to be easy to understand and work with, and can hold several DAGs as well as nodes with DAGs inside them. Before any changes can be processed you need to call engine.prepare(), doing so creates a Flat World from this Public World.
In the Flat World, all the different DAGs in the Public World have been combined into a single DAG. Dealing with things like connections between DAGs, and DAGs within nodes introduces a lot of complexity in the code. The purpose of the Flat World is to reduce that complexity by putting all nodes and edges into a single DAG. Instead of trying to solve the complex problem of nested and sibling DAGs, we’ve simply removed the problem!
After the Public World has been transformed into a Flat World, a Live World is immediately created from it.
The Live World is what actually gets processed in the end. Like the Flat World, this also has only one DAG, but unlike the Flat World, it has its own set of nodes. Each node in the Flat World can become several nodes in the Live World. Having a separate set of nodes for the Live World enables more reuse of logic and is more flexible.
When engine.prepare() is finished the Engine is ready to be processed. To do this, the user calls engine.run() repeatedly if they want to be able to pause processing, or engine.run_until_done() once if they want to wait until it’s done.
This post only describes the basic structure of the new architecture in broad strokes. There are many other interesting aspects, but those are posts for another day.
Conclusion
Here are the two biggest lessons I learned from this rewrite:
- Think twice before using shared memory.
- Instead of solving a complex problem, consider simplifying it.
I’m excited to have a much more promising architecture now, which will hopefully allow the project to proceed smoothly. The next update will focus on grid snapping!
Code and binaries are available. Do you have ideas for how the architecture could be improved further? Or maybe you have questions? If so, ping @**Lukas Orsvärn** in the Vismut Zulip. 😄